

Cross-Encoder Models for Efficient Query-to-Context Mapping
That title sounds like a mouthful but it is exactly what we are going to be discussing today. In short, we will look at how cross-encoder models work, some examples, and why they are relevant to query-to-context mapping which is a huge point of interest when we talk about improving AI model response quality. The ability for top models to be able to infer what your are referring to from conversation history is what makes them more natural convertors.
What is Query-to-Context Mapping?
Query-to-context mapping is the process of a model trying to figure out what part of the conversation history or prompt your follow-up question is referring to. Expect most AI tools like Cursor AI, Microsoft CoPilot, ChatGPT to have their own mapping process but what they have to do to provide contextually relevant responses to follow-up questions is map your question to the most likely snippet or part of the conversation history.
They do this for your benefit and theirs as well. The conversation history can become too long to fit into response context windows and still have quality and coherent responses. The larger models are much better even with these increasingly long message chains but there are more efficient ways to deal with this context.
Techniques for Context Management and Mapping
Embedding-Based Retrieval on Conversation History - Performing RAG on a vector database of chunks from the conversation history to find the most semantically similar chunks and hence, relevant parts of context to respond about.
Sliding Context Windows - The most recent n tokens (based on the model’s token limit) are kept in memory. It’s simple but effective for short sessions — used by default in many commercial LLMs.
Context Tagging - Each conversational chunk gets tagged with metadata (e.g., “tech”, “user preference”, “comparison”) for lightweight indexing.
Cross-Encoder Architecture
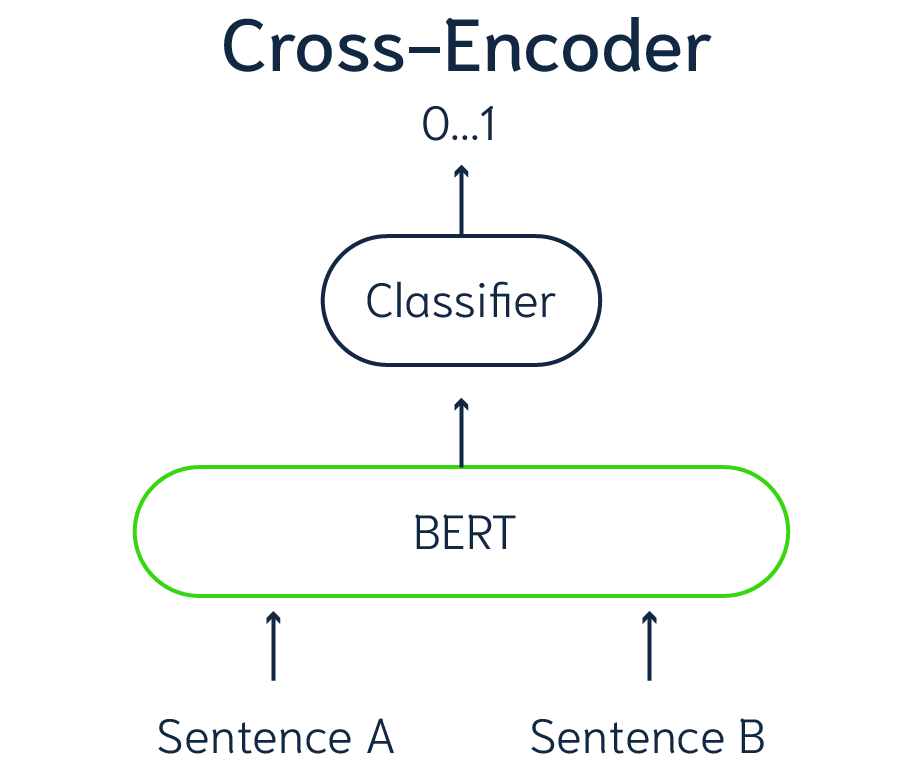
A cross-encoder is a neural network that processes two text inputs and outputs a score indicating their relationship or relevance.
1. The Inputs
The architecture is quite simple, the two sentence inputs are fed into a BERT model which aggregates both sentences into one piece of text.
[CLS] Query text [SEP] Context snippet [SEP]
[CLS]: Special classification token at the beginning.
[SEP]: Separators to distinguish segments (query vs. context).
2. Embedding the Text
Each token in the joint input is converted into embeddings:
Token embedding (what the word is)
Segment embedding (whether it belongs to query or context)
Position embedding (token’s place in sequence)
3. Transformer Layers
BERT applies multi-head self-attention across the entire joint sequence:
This is what enables deep interaction — the query can attend to every token in the context and vice versa.
Attention heads learn different semantic patterns (e.g. negation, comparison, entailment).
This is why cross-encoders outperform bi-encoders: they model interactions between query and context explicitly, not just as separate embeddings.
4. Classification Head
The output vector is a summary representation of the interaction between query and context. This is usually a numerical score where a higher number indicates that there is some relevance between the query and context and a lower score indicates a less relevant pairing.
Applying Cross-Encoders to Prompt Engineering
Query: "What is the inspiration behind Summere?"
Documents (Asycd content):
Document 1: "Summere is a groundbreaking AI art project that explores the intersection of technology and creative expression..." - 🔥 HIGH (Score: 5.3789)
Document 2: "The TEV1 AI image generator represents our latest advancement in creative technology..."- 🔵 LOW (Score: -11.4017)
Document 3: "Our blog covers various topics including prompt engineering, AI development..." - 🔵 LOW (Score: -11.5180)
This process goes beyond lexical similarity to reason about:
Entailment: “Is this claim supported by the document?”
Contradiction: “Is the document claiming something else?”
Semantic inference: “Is the document describing the inspiration behind Summere, even if the word ‘inspiration’ doesn’t appear?”
We are currently using this approach to enhance our AI chatbot experience in Asyra AI. We can use a cross-encoder to rank different segments in conversation history to direct the models focus as well as save on tokens.
Specifically, we are using it to deal with more vague queries in Asyra AI by mapping the query to the most logical snippet of text from the conversation history. We first chunk up the conversation history then we rank the chunks against the vague query e.g. “im not sure”
Then using the highest rank chunk as guidance to the model to say ‘Hey, the user gave a vague response to your last message but our analysis suggests that it was in response to [CHUNK 11]’
Why Does This Matter?
Even the most capable models right now struggle with ambiguous user queries and they end up distracting the model from the conversation leading it to start another. I asked ChatGPT to provide me a one sentence definition of photosynthesis. I highlighted the last part because this is where I was testing the ability to deal with vague queries but still stay on topic.
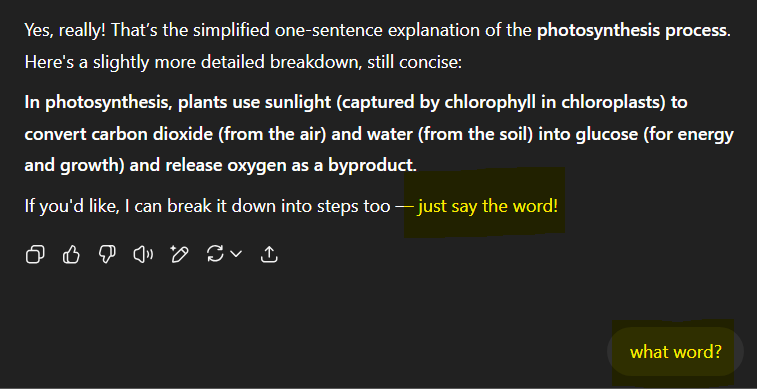
ChatGPT Example Part 1
ChatGPT Example Part 2
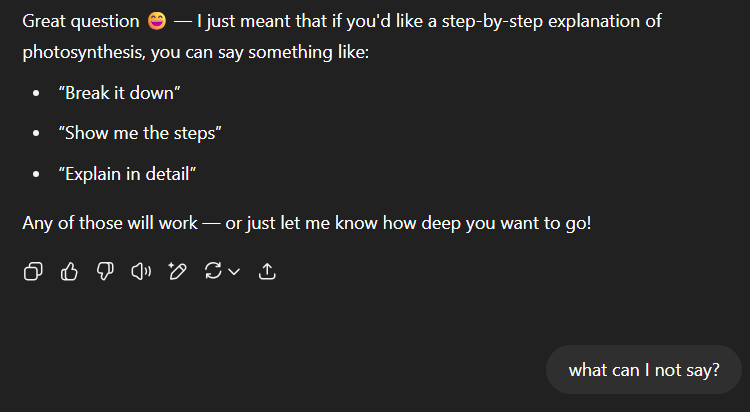
It caught what I meant when I said ‘what word?’ as I was looking to explore the different ways I could tell it to explain the process of photosynthesis. Next, I decided to ask about commands I can’t say to get the explanation for the photosynthesis process. It misinterpreted what I was asking for and generalised to just things I am not allowed to say.

ChatGPT Example Part 3
We see using cross-encoders as a method of bridging the intelligence gap even if it is relatively simple or lacking development. It is a starting point for us!
Try it Now
Asyra AI